# RQOptimizer 文档
# 简介
在现代量化交易当中,资产配置优化已经成为一个核心的投资执行步骤。在各类投资策略中,投资者通过输入投资目标、投资计划,和资产池,通过优化器计算得到最优资产权重,从而在满足投资限制和风险管理要求的前提下,实现投资效用的最大化。为了满足专业投资机构对于配置优化的需求,米筐科技开发了针对中国 A 股市场的股票组合优化器 RQOptimizer。其使用流程如下图所示:
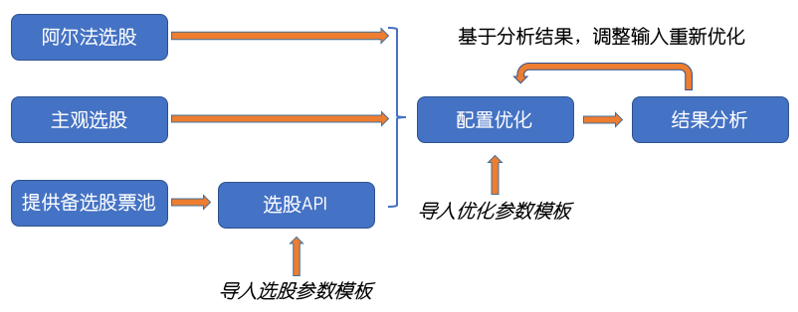
目前 RQOptimizer 提供的功能清单如下:
| 目标函数 | 约束条件 | 特色功能 |
|---|---|---|
| 方差最小化 追踪误差最小化 均值方差 夏普率最大化 信息率最大化 风格偏离最小化 风险平价 指标最大化 | 个股头寸约束 行业内个股头寸约束 风格约束 行业约束 换手率约束 追踪误差约束 基准成分股占比 | 投资白名单选股 股票优先级设置 自定义基准 因子优先级设置 软约束/硬约束设置 提供多套行业分类:中信一级,申万一级和申万一级(非银金融细分) |
# 亮点
米筐股票优化器 RQOptimizer 有如下亮点:
- 整合米筐多因子风险模型:整合米筐三套因子风险模型(日度、月度、季度),适应不同交易频率的策略,提升风险预测效果,构建风险优化组合;
- 对接自定义因子:可输入自定义股票因子得分构建优化组合。对接 RQFactor 多因子投研系统,实现因子投研-组合优化投研流程衔接;
- 提供便捷的选股功能:提供基于优化目标从投资白名单中筛选特定数量个股的功能。筛选中允许对个股设定不同优先级(详见选股 API介绍)。例如在指数增强中,可进行如下设置:
- 最高优先级:指数大权重股,降低追踪误差;
- 次优先级:存在超额收益个股,提升收益;
- 最低优先级:其它指数成分股,保证有足够数量股票,进一步控制追踪误差;
- 支持自定义基准:支持使用股票指数或自定义基准,帮助用户灵活挑选合适的比较基准组合,对策略进行风险敞口约束,或进行信息率最大化/追踪误差最小化等计算;
- 支持多套行业分类:支持申万一级和中信一级行业分类,并针对申万一级行业分类对于非银金融板块分类不够精细的问题,把非银金融板块进一步拆分为证券、保险、多元金融;
- 支持软硬约束设置:支持设置约束类型为硬约束或软约束。硬约束是优化解必须满足的约束条件;软约束是原约束无可行解的情况下,可以放松(relaxation)以获得可行解的约束条件。详见追踪误差约束部分介绍;
- 可与米筐投研产品整合使用:米筐科技在股票策略投资研究环节有多年的开发和产品积累,提供数据方案(RQData)、多因子研究(RQFactor)、以及回测引擎(RQAlpha)三大模块。米筐股票优化器可与其它投研模块高效整合,为机构搭建内部标准化投研流程提供灵活的解决方案。
基于米筐金工的研究,下表给出部分场景下优化器推荐使用方案:
| 使用场景 | 推荐方案 |
|---|---|
| 通过有效阿尔法因子获取超额收益,同时希望控制风格、行业、个股特殊风险 | 指标最大化 风格/行业约束 个股约束 |
| 通过有效阿尔法因子获取超额收益,同时认为部分风格/行业因子可产生超额收益,希望做风格/行业增强 | 指标最大化 增强风险因子正/负偏离约束 其它风险因子中性约束 个股约束 |
| 通过主观选股方式得到股票列表,希望通过优化器控制投资组合风险 | 方差最小化 风格/行业中性约束 个股约束 |
| 有投资白名单,没有选股因子,希望实现风格/行业增强的 Smarbeta 类型策略 | 选股 API 风格偏离最小化(因子优先级设置) 行业约束 个股约束 |
| 指数增强型策略,希望通过优化器控制追踪误差 | 追踪误差最小化 风格/行业中性约束 个股约束 基准成分股占比约束 |
| 希望以较低成本,较少数量的股票跟踪指数 | 追踪误差最小化 风格/行业中性约束 换手率约束 个股约束 |
| 市场处于下行阶段,希望通过优化器优化投资组合风险结构,提高风险分散程度,降低业绩回撤 | 方差或追踪误差最小化 风格/行业中性约束 个股约束 |
# 快速上手
# 安装产品
在安装 RQSDK (opens new window)的基础上,用户可通过如下命令实现优化器的一键安装:
rqsdk install rqoptimizer
更新 rqoptimizer 版本命令如下:
rqsdk update rqoptimizer
# 优化器 API
优化器 API 形式如下所示:
portfolio_optimize(order_book_ids, date, objective= MinVariance(), bnds=None, cons=None, benchmark=None, cov_model=CovModel.FACTOR_MODEL_DAILY)
参数
- order_book_ids (类型:list):一组股票代码列表(list of order book ids)。
- date(类型:string):优化日期(例如'2019-05-31')。
- objective(默认 MinVariance()):优化目标函数。
- bnds(类型:Dictionary,默认 None):个股头寸约束。
- cons(类型:list,默认 None):约束条件列表。
- benchmark (类型:string,默认为 None):基准组合。默认为 None,支持股票指数,例如沪深 300('000300.XSHG')或中证 500(’000905.XSHG’)。
- cov_model (默认为:CovModel.FACTOR_MODEL_DAILY):协方差模型。协方差估计使用多因子模型,支持的模型如下:
- CovModel.FACTOR_MODEL_DAILY - 日度预测模型(默认)
- CovModel.FACTOR_MODEL_MONTHLY- 可选择月度预测模型
- CovModel.FACTOR_MODEL_QUARTERLY - 季度预测模型
返回
pandas.Series - 优化权重(index 为 order_book_ids,value 为归一化的优化权重)。
示例
[In]
from rqoptimizer import *
import rqdatac
from rqdatac import *
rqdatac.init()
#优化日期
date = '2019-02-28'
#候选合约
pool = index_components('000906.XSHG',date)
#对组合中所有个股头寸添加相同的约束0~5%
bounds = {'*': (0, 0.05)}
#优化函数,风格偏离最小化,优化组合beta风格因子暴露度相对于基准组合高出1个标准差
objective = MinStyleDeviation({'size': 0, 'beta': 1, 'book_to_price': 0, 'earnings_yield': 0, 'growth': 0, 'leverage': 0, 'liquidity': 0, 'momentum': 0, 'non_linear_size': 0, 'residual_volatility': 0}, relative=True)
#约束条件,对所有风格因子添加基准中性约束,允许偏离±0.3个标准差
cons = [
WildcardStyleConstraint(lower_limit=-0.3, upper_limit=0.3, relative=True, hard=True)
]
portfolio_optimize(pool, date, bnds=bounds, cons=cons, benchmark='000300.XSHG',objective = objective)
[Out]
000001.XSHE 0.018249
000002.XSHE 0.010267
000006.XSHE 0.000141
000008.XSHE 0.000148
000009.XSHE 0.000085
...
603986.XSHG 0.000010
603993.XSHG 0.001689
# 选股
选股 API 形式如下所示:
stock_select(pool, targets, date, score, benchmark=None)
参数
- pool (类型:pandas.Series):投资组合备选股票池。index 为股票代码,value 为股票优先级系数,优先级系数范围为 0~2 的整数,不同股票取值可相同。取值为 0 表示最高优先级,依次类推。选股时首先选取优先级高的股票。
- targets (类型:list):选股目标列表。
- date (类型:string):日期。
- score :个股得分。
- benchmark (类型:string,默认 None):基准组合。支持股票指数,例如沪深 300('000300.XSHG')或中证 500(’000905.XSHG’)。
返回
list - 股票代码列表
示例
[In]
from rqoptimizer import *
from rqoptimizer.utils import *
import rqdatac
import pandas as pd
rqdatac.init()
def update_stock_pool(date):
index_weight = rqdatac.index_weights('000300.XSHG', date)
# 沪深300中权重大于3%的股票设定为第一优先级股票
first_priority_stock_pool = index_weight[index_weight >= 0.03].index.tolist()
first_priority_stock_pool = pd.Series(index=first_priority_stock_pool,data=0)
# 去除第一优先级股票后,其它股票中选取beta暴露度最高的前50只作为第二优先级股票
index_component_800 = rqdatac.index_components('000906.XSHG', date)
beta_exposure = rqdatac.get_factor_exposure(index_component_800,date,date,factors='beta')
beta_exposure.index = beta_exposure.index.droplevel('date')
second_priority_stock_pool = beta_exposure['beta'].drop(first_priority_stock_pool.index).sort_values()[-50:]
second_priority_stock_pool = pd.Series(index=second_priority_stock_pool.index, data=1)
# 中证800中去除前两个优先级后,剩余股票作为优先级最低的股票
last_priority_stock_pool = list(set(index_component_800).difference(set(first_priority_stock_pool.index)).difference(set(second_priority_stock_pool.index)))
last_priority_stock_pool = pd.Series(index=last_priority_stock_pool, data=2)
stock_pool = pd.concat([first_priority_stock_pool, second_priority_stock_pool, last_priority_stock_pool])
return stock_pool
date = '2019-02-28'
stock_pool = update_stock_pool(date)
#目标选取120只股票,包含5只银行股
targets=[TotalStockCountTarget(120),
IndustryStockCountTarget(industry='银行',classification= IndustryClassification.SWS, count=5)]
# 个股风险贡献得分
score = RiskScore()
stock_select(stock_pool, targets, date, score, benchmark=None)
[Out]
['601988.XSHG',
'601288.XSHG',
'601328.XSHG',
'601398.XSHG',
'601818.XSHG',
'600519.XSHG',
...
'600606.XSHG',
'002254.XSHE',
'601872.XSHG']
# 约束条件
优化器约束条件中包含可选和不可选两类,具体说明如下:
不可选条件
- 不能做空个股,不能加杠杆做多个股。通用公式如下,其中为投资组合中个股的权重:
- 投资组合为满仓组合。通用公式如下,若用户希望得到不满仓的优化权重,可对返回的优化结果乘以股票仓位比例。例如,若用户希望的现金和股票占比分别为 20%和 80%,则可对股票优化权重统一乘以 0.8:
可选条件
- 个股头寸约束。通用公式如下,其中 和分别为用户所选择的约束条件上下限:
- 基准成分股占比约束。通用公式如下:
- 风格暴露约束。通用公式如下,其中为投资组合中个股 i 的风格暴露度:
- 行业权重约束。通用公式:
- 行业内个股权重约束。通用公式:
- 追踪误差上限约束。通用公式如下,其中 为收益协方差矩阵:
- 换手率上限约束。通用公式如下,其中为和期曾持仓的股票总数量,和分别为和期股票的权重:
- 指数权重约束。通用公式如下,其中 和 分别为用户所选择的约束条件上下限:
- 自定义组合权重约束。通用公式如下,其中 和 分别为用户所选择的约束条件上下限:
成交量约束。在进行换手的情况下考虑,对换手的每个股票数量占该股票前 i 个交易日成交量的百分比进行约束
成交量市值约束。在进行换手的情况下考虑,对换手的每个股票市值占该股票前 i 个交易日日总市值的百分比进行约束
# 个股头寸约束
bnds(Dictionary|None)
类型
Dictionary 或者 None,默认为 None。输入 Dictionary 时 key 为 order book ids,value 为对应股票的上下限组成的 tuple。当 key 为 '*' 时,表示所有未指定约束的股票均设置相同的权重上下限。
示例
在优化中设置中国平安股票上下限为 5~ 10%,其它个股上下限约束为 0~5%,则输入个股约束如下所示:
bnds={"000001.XSHG":(0.05,0.1),"*":(0,0.05)}
# 约束列表
cons(list|None)
类型
list 或者 None,默认为 None。输入 list 时支持的约束类型会在下面介绍。
# 年化追踪误差上限约束
TrackingErrorLimit(upper_limit, hard=True)
参数
- upper_limit(类型:float):年化追踪误差上限(浮点数),例如 upper_limit 设置为 0.15,即表示年化追踪误差上限为 15%。
- hard(类型:Boolean,默认 True):是否设置为硬约束。默认为 True,即优化结果不满足该约束时报错;若选择 False,则优化结果不满足该约束时,去掉该约束重新优化。
示例
以设置年化追踪误差上限为 5%,类型为硬约束为例,输入示例如下:
cons = [TrackingErrorLimit(upper_limit=0.05, hard=True)]
当追踪误差约束类型为硬约束时,若优化器无法得到可行解时将抛出异常,导致优化器中断策略回测。为避免这种情况出现,优化器支持添加多个追踪误差限制。例如用户希望优化中可以满足追踪误差低于 8%的约束,若该约束无法满足,则允许放松追踪误差约束至 12%。其输入示例如下:
cons = [TrackingErrorLimit(upper_limit=0.08, hard=False),TrackingErrorLimit(upper_limit=0.12, hard=True)]
上述软硬约束的设置形式同样适用于下面即将介绍的换手率约束、风格约束、以及行业约束。
# 换手率约束
TurnoverLimit(current_holding, upper_limit, hard=True)
参数
- current_holding (类型:pandas.Series):初始仓位权重,类型为 pandas.Series, 其中 index 是股票合约代码,value 是股票归一化权重。
- upper_limit (类型:float):换手率上限,例如 upper_limit 为 0.5 表示换手率上限为 0.5。
- hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
示例
以设置换手率约束上限为 0.3,类型为硬约束为例,其输入示例如下:
cons = [TurnoverLimit(current_holding=current_holding, upper_limit=0.3, hard=True)]
其中 current_holding 变量类型为 pandas.Series,输入示例如下表所示:
| order_book_id | weight |
|---|---|
| 000001.XSHE | 0.0940 |
| 000002.XSHE | 0.1683 |
| ... | ... |
current_holding=pd.Series(data=[0.0940,0.01683,...], index=pd.Index(['000001.XSHE','000002.XSHE',...],name='order_book_id'), name='weight')
# 基准成分股权重限制
BenchmarkComponentWeightLimit(lower_limit, hard=True)
参数
- lower_limit(类型:float):基准成分股占比下限。若输入为 0.8,即优化结果中基准成分股权重之和不低于 80%。
- hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
示例
cons = [BenchmarkComponentWeightLimit(lower_limit=0.8, hard=True)]
# 行业权重约束
IndustryConstraint(industries, lower_limit=None, upper_limit=None, relative=False, classification=IndustryClassification.SWShard=True)
参数
- industries (类型:string list or string):行业名称,只对单个行业有限制时,输入单个行业名称(字符串),若对多个行业有限制,输入多个行业名称的列表。
- lower_limit (类型:float,默认为 None):行业权重下限。
- upper_limit (类型:float,默认为 None):行业权重上限。
- relative (类型:Boolean,默认为 False):是否相对于基准的行业偏离约束。默认为 False。例如银行业的权重上下限分别设置为 0 和 0.02,当 relative 取值为 True 时,表示投资组合相对于基准组合的银行业权重的允许偏离为 0~2% ;若 relative 为 False,即表示投资组合的银行业目标权重约束为 0~2%。
- classification (默认为 'IndustryClassification.SWS'):选择行业分类标准。默认使用申万一级行业分类('IndustryClassification.SWS'),可选中信一级行业分类('IndustryClassification.ZX')或申万一级行业分类(非银金融拆分成证券、保险和多元金额)('IndustryClassification.SWS_1)。
- hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
扩展
可指定除exclude列表外其他行业的权重限制,与IndustryConstraint 配合使用,可方便实现对所有行业的权重限制,API 如下:
WildcardIndustryConstraint(exclude=None, lower_limit=None, upper_limit=None, relative=False, classification=IndustryClassification.SWS, hard=True)
其中参数 exclude (类型:list,默认 None)为排除的行业名称列表,其他参数含义与 IndustryConstraint 的参数含义一样。
示例
行业约束设置与风格约束形式一致。按照中信一级行业分类,以基准行业中性,允许偏离为 ±1%为例,其输入形式如下:
cons = [WildcardIndustryConstraint(lower_limit=-0.01, upper_limit=0.01, relative=True, classification=IndustryClassification.ZX,hard=True)]
# 行业内个股权重约束
IndustryComponentLimit(industry,lower_limit=None,upper_limit=None,classification=IndustryClassification.SWS,hard=True)
参数
industry (类型:string):行业名称(字符串)。
lower_limit (类型:float,默认为 None):个股占行业权重比例下限。
upper_limit (类型:float,默认 None):个股占行业权重比例上限。例如当前银行业权重为 20%,银行业内个股占行业权重比例的上下限分别为 10~30%,则银行业内个股在组合内实际权重上下限为 2%-6%。
classification 默认为 'IndustryClassification.SWS'(申万一级行业分类)):行业分类标准(参数解释见IndustryConstraint部分)。
hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
示例
行业内个股权重约束设置与行业约束设置类似,按照申万一级行业分类标准,银行业内个股占银行业总权重 10~30%为例,其输入形式如下:
cons = [IndustryComponentLimit (industry='银行',lower_limit=0.1, upper_limit=0.3, classification=IndustryClassification.SWS, hard=True)]
# 风格暴露度约束
StyleConstraint(styles, lower_limit=None, upper_limit=None, relative=False, hard=True)
风格字段及解释如下表:
| 风格因子字段 | 解释 |
|---|---|
| beta | 个股/投资组合收益对基准组合价格变动的敏感度 |
| momentum | 股票收益变化的总体趋势特征 |
| size | 上市公司的市值规模 |
| earnings_yield | 上市公司的营收能力 |
| residual_volatility | 个股残余收益的波动程度 |
| growth | 上市公司的营收增长情况 |
| book_to_price | 上市公司的股东权益-市值比,反映其估值水平 |
| leverage | 上市公司企业负债占资产比例,反映企业的经营杠杆率 |
| liquidity | 股票换手率,反映个股交易的活跃程度 |
| non_linear_size | 反映中等市值股票和大/小市值股票的表现差异 |
参数
- styles (类型:string 或 list):风格列表,支持风格字段及其解释见上表。
- lower_limit (类型:float,默认为 None):风格暴露度约束下限。
- upper_limit (类型:float,默认为 None):风格暴露度约束上限。
- relative (类型:Boolean,默认为 False):是否相对于基准的风格偏离约束。默认为 False。例如 beta 因子的风格暴露度上下限取值为 0.1~0.3 ,若 relative 为 True,即表示投资组合相对于基准组合的 beta 暴露度约束为高 0.1~0.3 个标准差;若 relative 为 False,即表示投资组合的 beta 因子目标暴露度约束为 0.1~0.3 个标准差。
- hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
扩展
可指定除exclude列表外的其它风格因子暴露度上下限。与WildcardIndustryConstraint类似。
WildcardStyleConstraint(exclude, lower_limit=None, upper_limit=None, relative=False, hard=True)
其中参数exclude (类型:list)为排除的风格因子列表,其他参数含义与StyleConstraint的参数含义一样。
示例
对特定风格因子添加约束。以设置贝塔因子暴露度正偏离 0.4 ~ 0.7 个标准差,市值因子暴露度在-0.3~0.3 之间,其他因子无约束为例,其输入示例如下:
cons = [StyleConstraint('beta', lower_limit=0.4,upper_limit=0.7, relative=False,hard=True),StyleConstraint('size', lower_limit=-0.3,upper_limit=0.3,relative=False,hard=True)]
对所有风格因子添加基准中性约束,其输入形式如下:
cons = [WildcardStyleConstraint(lower_limit=-0.3, upper_limit=0.3, relative=True, hard=True)]
对特定风格因子添加正/负偏离约束,对其它风格因子添加基准中性约束。例如用户认为贝塔因子正暴露能增强组合收益,则设置贝塔因子暴露度相对于基准正偏离 0.4~0.7 个标准差,其它因子与基准保持中性,允许偏离 ±0.3 个标准差,则输入示例如下:
cons = [StyleConstraint('beta', lower_limit=0.4,upper_limit=0.7,relative=True,hard=True),WildcardStyleConstraint(exclude=['beta'], lower_limit=-0.3, upper_limit=0.3, relative=True, hard=True)]
# 指数权重约束
IndexComponentLimit(index_code,lower_limit=None,upper_limit=None, hard=True)
参数
- index_code(类型:string):指数代码。
- lower_limit (类型:float,默认为 None):指数成分总占比下界。
- upper_limit (类型:float,默认 None):指数成分总占比上界。
- hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
示例
以设置沪深 300 权重为 10%-30%,类型为硬约束为例,输入示例如下:
cons = [IndexComponentLimit(index_code = '000300.XSHG',upper_limit = 0.3,lower_limit = 0.1, hard=True)]
# 自定义组合权重约束
StockPoolLimit (stock_list, lower_limit=None, upper_limit=None, hard=True)
参数
- stock_list(类型:list):自定义股票列表。
- lower_limit (类型:float,默认为 None):组合内股票权重占比下界。
- upper_limit (类型:float,默认 None):组合内股票权重占比上界。
- hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
示例
与指数权重约束类似,用户自定义一个股票池,对其中的成分股占比进行上下限头寸约束为 10%-30%,输入示例如下:
cons = [StockPoolLimit(stock_list=['300357.XSHE', '001914.XSHE', '002901.XSHE', '002552.XSHE', '300482.XSHE'],
upper_limit=0.3, lower_limit=0.1, hard=True)]
# 成交量约束
TransactionVolumeLimit( current_holding=None, cash=None, window=1, stock_list=None, upper_limit=None, hard=True)
参数
- current_holding(类型:float):当前持仓,应传入股票数量而非权重。
- cash(类型:float,默认为 1):可用资金数量。
- window(类型:float,默认为 1):前几个交易日的平均交易量。
- stock_list (类型:float,默认为 None):需要约束的股票列表。
- upper_limit (类型:float,默认 None):成交量占比上界。
- hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
示例
以设置交易量约束为 0.01,类型为硬约束为例,输入示例如下:
cons = [TransactionVolumeLimit(current_holding=current_holding_num, upper_limit=0.01, cash=1000000, window=1,
stock_list=['300482.XSHE', '300659.XSHE', '000001.XSHE', '600004.XSHG', '603369.XSHG', '600529.XSHG'])]
# 成交量市值约束
TransactionMarketValueLimit (current_holding=None, upper_limit=None, cash=None, window=1, stock_list=None, hard=True)
参数
- current_holding(类型:float):当前持仓,应传入股票数量而非权重。
- cash(类型:float,默认为 1):可用资金数量
- window(类型:float,默认为 1):前几个交易日的平均交易量。
- stock_list (类型:float,默认为 None):需要约束的股票列表。
- upper_limit (类型:float,默认 None):交易市值占该股票总市值百分比上界
- hard (类型:Boolean,默认 True):约束类型,默认为 True(参数解释见TrackingErrorLimit部分)。
示例
以设置交易量市值约束为 0.05,类型为硬约束为例,输入示例如下:
cons = [TransactionMarketValueLimit (current_holding=current_holding_num, upper_limit=0.05, cash=1000000, window=1,
stock_list=['300482.XSHE', '300659.XSHE', '000001.XSHE', '600004.XSHG', '603369.XSHG', '600529.XSHG'])]
# 优化目标函数
objective(默认MinVariance())
优化目标函数,支持的优化函数在下面详细介绍。
# 方差最小化
MinVariance()
当用户不指定objective时默认用的是MinVariance()作为优化函数。
参数
无
# 均值方差
MeanVariance(expected_returns, window=126, risk_aversion_coefficient=1)
参数
- expected_returns(类型:pandas.Series):个股预期年化收益率,index 是股票 order book ids,value 是预期年化收益率(浮点数)。若预期收益率存在缺失值,则将缺失值以 0 填补。若预期收益全部缺失,则优化问题等价于方差最小化问题。若用户不传入该参数,则使用历史收益率估计。
- window(类型:int,默认 252):预期年化收益率估计所使用的的历史收益率时间长度。仅在没有设置 expected_returns 参数时生效。默认为 252 个交易日,即使用最近 252 个交易日的个股日收益率计算预期年化收益率。
- risk_aversion_coefficient (类型:float,默认 1):风险厌恶系数。
示例
data = [ 0.02415139, 0.01156958, -0.01172305, 0.00391858, -0.00044541,0.0 , 0.00153166, -0.00153848,-0.008744,0.004233]
stock_list =['601555.XSHG','300124.XSHE','002415.XSHE','600028.XSHG','002916.XSHE','600655.XSHG','600176.XSHG','601088.XSHG','002456.XSHE','601658.XSHG']
expected_returns = pd.Series(data, index=pd.Index(stock_list,name='order_book_id'))
objective = MeanVariance(expected_returns=expected_returns)
# 风险平价
RiskParity()
参数
无
示例
objective = RiskParity()
# 追踪误差最小化
MinTrackingError()
参数
无
示例
objective = MinTrackingError()
# 最大化信息比率
MaxInformationRatio(expected_active_returns, window=252)
参数
- expected_active_return (类型:pandas.Series):个股预期年化主动收益率,index 是股票 order book ids,value 是个股预期年化主动收益率(浮点数)。若预期主动收益率存在缺失值,则将缺失值以 0 填补。若用户不传入该参数,则使用历史收益率估计。
- window(类型:int,默认 252):预期年化主动收益率估计的历史收益率时间长度。仅在没有设置 expected_active_returns 参数时生效。默认为 252 个交易日,即使用最近 252 个交易日的个股日收益率计算预期年化主动收益率。
示例
data = [ 0.02415139, 0.01156958, -0.01172305, 0.00391858, -0.00044541,0.0 , 0.00153166, -0.00153848,-0.008744,0.004233]
stock_list =['601555.XSHG','300124.XSHE','002415.XSHE','600028.XSHG','002916.XSHE','600655.XSHG','600176.XSHG','601088.XSHG','002456.XSHE','601658.XSHG']
expected_active_return = pd.Series(data, index=pd.Index(stock_list,name='order_book_id'))
objective = MaxInformationRatio(expected_active_returns = expected_active_return)
# 最大化夏普率
MaxSharpeRatio(expected_returns, window=252)
expected_returns(类型:pandas.Series):个股预期年化收益率,index 是股票 order book ids,value 是预期年化收益率(浮点数)。若预期收益率存在缺失值,则将缺失值以 0 填补。若用户不传入该参数,则使用历史收益率估计。
window(类型:int,默认 252):预期年化收益率估计的历史收益率时间长度。仅在没有设置 expected_returns 参数时生效。默认为 252 个交易日,即使用最近 252 个交易日的个股日收益率计算预期年化收益率。
示例
objective = MaxSharpeRatio(window=200)
# 指标最大化
MaxIndicator(indicator_series)
参数
- indicator_series (类型:pandas.Series):股票指标得分序列。指标序列 index 为股票 order book ids,value 为指标得分,不同股票指标得分可相同,指标得分的变量类型可为浮点数或整数。需要注意的是,若用户传入的个股指标得分存在数量级的差异,可能会导致优化权重过分集中于部分得分较高的个股。因此建议用户在输入前先对指标中的离群值进行处理。此外,若指标中存在缺失值,则剔除出现缺失的股票后再进行优化。
示例
date = '2014-07-16' # 优化日期
# 获取前一交易日中证800成分股的净利润增长率(TTM)
previous_date = rqdatac.get_previous_trading_date(date)
index_component = rqdatac.index_components('000906.XSHG', previous_date)
indicator_series = rqdatac.get_factor(index_component, 'net_profit_growth_ratio_ttm', previous_date,previous_date,expect_df=False).dropna()
pool = sorted(indicator_series.index)
# 个股指标得分范围调整至0.1-1.1,避免权重过分集中于部分指标得分较大的个股
adjusted_series = ((indicator_series.loc[pool] - indicator_series.loc[pool].min()) / (indicator_series.loc[pool].max() - indicator_series.loc[pool].min())) + 0.1
objective=MaxIndicator(indicator_series=adjusted_series)
# 风格偏离最小化
MinStyleDeviation(target_style, relative=False,priority=None)
参数
- target_style (类型:pandas.Series):目标风格暴露度,index 为风格因子字段名称(见风格暴露度约束处的介绍),value 为目标风格暴露度,以标准差为单位。
- relative(类型:bool,False):是否以相对基准的风格暴露偏离度为优化目标。默认为 False。例如 beta 因子的 target_style 取值为 0.3,若 relative 为 True,即表示优化组合 beta 风格因子暴露度相对于基准组合高出 0.3 个标准差 ;若 relative 为 False,即表示优化组合的 beta 因子目标暴露度为 0.3 个标准差。
- priority(类型:pandas.Series,默认 None):风格因子优先级设置。取值范围为 0~9 之间的整数,9 为最高优先级,0 为最低优先级,未指定的因子优先级默认为 5。风格因子的优先级越高,则在优化中满足其暴露度目标的重要性越高。
示例
target_style = pd.Series({'size': 0, 'beta': 1, 'book_to_price': 0, 'earnings_yield': 0, 'growth': 0, 'leverage': 0,'liquidity': 0, 'momentum': 0, 'non_linear_size': 0, 'residual_volatility': 0})
objective = MinStyleDeviation({'size': 0, 'beta': 1, 'book_to_price': 0, 'earnings_yield': 0, 'growth': 0, 'leverage': 0, 'liquidity':0,'momentum': 0, 'non_linear_size': 0, 'residual_volatility': 0}, relative=True, priority=target_style)
# 选股目标列表
target
选股目标列表,支持的类型在下面详细介绍。
# 选股数量目标
TotalStockCountTarget(count)
参数
count (类型:int):总选股数目选择。例如 count 取值为 120,即从备选股票池选取 120 只股票。
# 行业内选股目标
IndustryStockCountTarget(industry, classification, count)
参数
- industry (类型:string):行业名称。行业名称需与行业分类参数 classification 匹配。
- classification :行业分类标准。可选择申万一级行业分类('IndustryClassification.SWS'),中信一级行业分类('IndustryClassification.ZX'),以及申万一级行业分类(拆分非银金融)('IndustryClassification.SWS_1')。
- count (类型:int):行业目标选股数目。
示例
行业目标选股数目。例如计划选取股票总数量为 120 只,并按照中信一级行业分类,选取 5 只银行业股票,则输入形式如下:
targets=[TotalStockCountTarget(120),
IndustryStockCountTarget(industry='银行',classification= IndustryClassification.ZX, count=5)]
# 个股得分
score
个股得分,支持的类型在下面详细介绍。
# 个股得分序列
score_series
类型:pandas.Series,index 为备选股票代码,value 为个股得分。股票得分不能相同,得分类型可为整数或浮点数。
示例
data=[1.1,0.5,2,3.1,2.2,3,1.2,0.8,0.2,3.2]
score = pd.Series(data, index=pd.Index(index_components('000300.XSHG')[0:10],name='order_book_id'))
若用户不输入个股得分序列,则可根据不同的优化目标选择下述几种输入。
# 个股风格暴露度得分
TargetStyleScore(target_style, relative=False)
选择该选股方式时,个股风格暴露度与目标风格暴露度越接近,个股得分越高。当优化目标为风格偏离最小化时,可考虑该选股方式。
参数
- target_style (类型:pandas.Series):目标风格暴露度,index 为风格因子名称(支持的风格因子见风格暴露度约束),value 为目标风格暴露度。
- relative (类型:bool,默认 False):是否相对于基准的风格偏离目标。默认为 False。
示例
target_style = pd.Series({'size': 0, 'beta': 1, 'book_to_price': 0, 'earnings_yield': 0, 'growth': 0, 'leverage': 0,'liquidity': 0, 'momentum': 0, 'non_linear_size': 0, 'residual_volatility': 0})
score = TargetStyleScore(target_style=target_style, relative=True)
# 个股风险贡献得分
RiskScore()
选择该选股方式时,个股在等权重组合中波动率贡献越低,个股得分越高。当优化目标为波动率最小化或风险平价时,可考虑该选股方式。
示例
score = RiskScore()
# 个股主动风险贡献得分
ActiveRiskScore()
个股主动风险贡献得分。选择该选股方式时,个股在等权重组合中追踪误差贡献越低,个股得分越高。当优化目标为追踪误差最小化时,可选择该方法对个股打分。
示例
score = ActiveRiskScore()
# 收益风险比得分
RiskReturnScore(expected_returns=None, window=126)
选择该选股方式时,个股预期收益率与个股在等权重组合中的波动率贡献的比值越高,个股得分越高。当优化目标为均值方差或夏普率最大化时,可选择该方法对个股打分。
参数
- expected_returns (类型:pandas.Series)个股预期收益率(参数解释见文中均值方差部分的介绍),若用户不传入该参数,则使用历史收益率估计。
- window(类型:int,默认 252):收益率估计所使用的的历史数据的时间长度(参数解释见文中均值方差部分的介绍)。
示例
data = [ 0.02415139, 0.01156958, -0.01172305, 0.00391858, -0.00044541,0.0 , 0.00153166, -0.00153848,-0.008744,0.004233]
stock_list =['601555.XSHG','300124.XSHE','002415.XSHE','600028.XSHG','002916.XSHE','600655.XSHG','600176.XSHG','601088.XSHG','002456.XSHE','601658.XSHG']
expected_returns = pd.Series(data, index=pd.Index(stock_list,name='order_book_id'))
score = RiskReturnScore(expected_returns)
# 个股主动收益风险比得分
ActiveRiskReturnScore(expected_active_returns=None, window=252)
选择该选股方式时,个股预期主动收益率与个股在等权重组合中的追踪误差贡献的比值越高,个股得分越高。当优化目标为信息比率最大化时,可选择该方法。
参数
- expected_active_returns (类型:pandas.Series):个股预期主动收益率(参数解释见上文中信息比率最大化模型),若用户不传入该参数,则使用历史收益率估计。
- window(类型:int,默认 252):收益率估计所使用的的历史数据的时间长度(参数解释见文中均值方差部分的介绍)。
# 代码示例
# 净利润增长率指数增强策略
import rqdatac
from rqoptimizer import *
from rqdatac import *
rqdatac.init()
### 净利润增长率指数增强策略
def generate_stock_pool(date, indicator_series, stock_number):
industry_classification = rqdatac.zx_instrument_industry(indicator_series.index.tolist(), date)['first_industry_name']
index_weight = rqdatac.index_weights('000300.XSHG', date)
# 优先选入沪深300成分股中权重大于3%的股票
prioritized_stock_pool = index_weight[index_weight >= 0.03].index.tolist()
prioritized_stock_industry = industry_classification.loc[prioritized_stock_pool]
remaining_indicator_series = indicator_series.drop(prioritized_stock_pool)
selected_stock = prioritized_stock_pool
for i in list(industry_classification.unique()):
# 除优先选入股票外,在每个行业选取指标得分最高的股票,使得每一个行业股票总数量为5
industry_prioritized_stock = prioritized_stock_industry[prioritized_stock_industry == i].index.tolist()
industry_stocks = industry_classification[industry_classification==i].drop(industry_prioritized_stock)
industry_selected_stock = remaining_indicator_series.loc[industry_stocks.index].sort_values()[-(stock_number-len(industry_prioritized_stock)):].index.tolist()
selected_stock = selected_stock + industry_selected_stock
return selected_stock
bounds = {'*': (0, 0.05)}
date = '2014-07-16' # 优化日期
# Wildcard的exclude列表为空,即对所有风格/行业设置相同的约束,其中使用中信行业分类
cons = [
WildcardIndustryConstraint(lower_limit=-0.01, upper_limit=0.01, relative=True, hard=False),
WildcardStyleConstraint(lower_limit=-0.3, upper_limit=0.3, relative=True, hard=False)
]
# 获取前一交易日中证800成分股的净利润增长率(TTM)
previous_date = rqdatac.get_previous_trading_date(date)
index_component = rqdatac.index_components('000906.XSHG', previous_date)
indicator_series = rqdatac.get_factor(index_component, 'net_profit_growth_ratio_ttm', previous_date,previous_date,expect_df=False).dropna()
selected_stock = generate_stock_pool(previous_date, indicator_series, stock_number=5)
# 个股指标得分范围调整至0.1-1.1,避免权重过分集中于部分指标得分较大的个股
adjusted_series = ((indicator_series.loc[selected_stock] - indicator_series.loc[selected_stock].min()) / (
indicator_series.loc[selected_stock].max() - indicator_series.loc[selected_stock].min())) + 0.1
portfolio_weight = portfolio_optimize(selected_stock, date, bnds=bounds, cons=cons, benchmark='000300.XSHG', objective=MaxIndicator(indicator_series=adjusted_series))
# 贝塔风格增强策略
from rqoptimizer import *
from rqoptimizer.utils import *
import rqdatac
from rqdatac import *
import pandas as pd
rqdatac.init()
def update_stock_pool(date):
index_weight = rqdatac.index_weights('000300.XSHG', date)
# 沪深300中权重大于3%的股票设定为第一优先级股票
first_priority_stock_pool = index_weight[index_weight >= 0.03].index.tolist()
first_priority_stock_pool = pd.Series(index=first_priority_stock_pool,data=0)
# 去除第一优先级股票后,其它股票中选取beta暴露度最高的前50只作为第二优先级股票
index_component_800 = rqdatac.index_components('000906.XSHG', date)
beta_exposure = rqdatac.get_factor_exposure(index_component_800,date,date,factors='beta')
beta_exposure.index = beta_exposure.index.droplevel('date')
second_priority_stock_pool = beta_exposure['beta'].drop(first_priority_stock_pool.index).sort_values()[-50:]
second_priority_stock_pool = pd.Series(index=second_priority_stock_pool.index, data=1)
# 中证800中去除前两个优先级后,剩余股票作为优先级最低的股票
last_priority_stock_pool = list(set(index_component_800).difference(set(first_priority_stock_pool.index)).difference(set(second_priority_stock_pool.index)))
last_priority_stock_pool = pd.Series(index=last_priority_stock_pool, data=2)
stock_pool = pd.concat([first_priority_stock_pool, second_priority_stock_pool, last_priority_stock_pool])
return stock_pool
# 生成行业选股约束
def generate_industry_selected_stock(stock_number):
industry_factors = ['农林牧渔', '采掘', '化工', '钢铁', '有色金属', '电子', '家用电器', '食品饮料', '纺织服装', '轻工制造', '医药生物', '公用事业', '交通运输', '房地产', '商业贸易', '休闲服务','综合', '建筑材料', '建筑装饰', '电气设备', '国防军工', '计算机', '传媒', '通信', '银行', '证券','保险','多元金融', '汽车', '机械设备']
industry_selected_stock = []
for i in industry_factors:
industry_stock = IndustryStockCountTarget(i, IndustryClassification.SWS_1, stock_number)
industry_selected_stock.append(industry_stock)
return industry_selected_stock
date = '2019-02-28' # 优化日期
stock_pool = update_stock_pool(date)
# 设定每个行业中选择5只股票
industry_selected_stock = generate_industry_selected_stock(stock_number=5)
target_style = pd.Series({'size': 0, 'beta': 1, 'book_to_price': 0, 'earnings_yield': 0, 'growth': 0, 'leverage': 0,
'liquidity': 0, 'momentum': 0, 'non_linear_size': 0, 'residual_volatility': 0})
stock_list = stock_select(stock_pool, industry_selected_stock, date, TargetStyleScore(target_style=target_style, relative=True),benchmark='000300.XSHG')
bounds = {'*': (0, 0.05)}
# 添加行业约束
cons = [WildcardIndustryConstraint(lower_limit=-0.01, upper_limit=0.01, relative=True, hard=False)]
objective = MinStyleDeviation({'size': 0, 'beta': 1, 'book_to_price': 0, 'earnings_yield': 0, 'growth': 0, 'leverage': 0, 'liquidity': 0, 'momentum': 0, 'non_linear_size': 0, 'residual_volatility': 0}, relative=True, priority=target_style)
portfolio_weight = portfolio_optimize(stock_list, date, bnds=bounds, cons=cons, benchmark='000300.XSHG', objective=objective)